
Just now, NVIDIA CUDA has received the largest update in history!

英偉達發佈 CUDA Toolkit 13.1,稱為 20 年來最大更新。更新包括 CUDA Tile 編程模型、Green Context 的 Runtime API 暴露、cuBLAS 仿真功能,以及重寫的 CUDA 編程指南。CUDA Tile 允許開發者在更高層次編寫算法,抽象化專用硬件細節。
幾個小時前,NVIDIA CUDA Toolkit 13.1 正式發佈,英偉達官方表示:「這是 20 年來最大的一次更新。」
這個自 2006 年 CUDA 平台誕生以來規模最大、最全面的更新包括:
- NVIDIA CUDA Tile 的發佈,這是英偉達基於 tile 的編程模型,可用於抽象化專用硬件,包括張量核心。
- Runtime API exposure of green contexts(是指把所謂的 Green Context「指輕量級的、可併發調度的上下文或執行環境」暴露給外部調用者使用。)
- NVIDIA cuBLAS 中的雙精度和單精度仿真。
- 一本完全重寫的 CUDA 編程指南 ,專為 CUDA 新手和高級程序員設計。
下面我們就來具體看看。
CUDA Tile
CUDA Tile 是 NVIDIA CUDA Toolkit 13.1 最核心的更新。它是一種基於 tile 的編程模型,能夠以更高的層次編寫算法,並抽象化專用硬件(例如張量核心)的細節。
英偉達博客解釋説:CUDA Tile 可讓開發者在高於 SIMT(單指令多線程)的層級編寫 GPU 核函數。
在目前的 SIMT 編程中,開發者通常通過劃分數據並定義每個線程的執行路徑來指定核函數。
而藉助 CUDA Tile,開發者可以提升代碼的抽象層級,直接指定被稱為「Tile」的數據塊。只需指定要在這些 Tile 上執行的數學運算,編譯器和運行時環境會自動決定將工作負載分發到各個線程的最佳方式。
這種 Tile 模型屏蔽了調用 Tensor Core 等專用硬件的底層細節,並且 Tile 代碼將能夠兼容未來的 GPU 架構。
CUDA 13.1 包含兩個用於 Tile 編程的組件:
- CUDA Tile IR:一種用於 NVIDIA GPU 編程的全新虛擬指令集架構(ISA)。
- cuTile Python:一種新的領域特定語言(DSL),用於在 Python 中編寫基於數組和 Tile 的核函數。
編譯的 Tile 路徑可以融入完整的軟件棧,與 SIMT 路徑對應。
這是該軟件的首個版本,其包含以下注意事項:
- CUDA Tile 僅支持 NVIDIA Blackwell(計算能力 10.x 和 12.x)系列產品。未來的 CUDA 版本將擴展對更多架構的支持。
- 目前的開發重點聚焦於 AI 算法的 Tile 編程。英偉達表示在未來的 CUDA 版本中將持續增加更多特性、功能並提升性能。
- 英偉達計劃在即將發佈的 CUDA 版本中引入 C++ 實現。
為什麼要為 GPU 引入 Tile 編程?
CUDA 向開發者提供了單指令多線程(SIMT)硬件和編程模型。這種模式要求(同時也允許)開發者以最大的靈活性和針對性,對代碼的執行方式進行細粒度控制。然而,編寫高性能代碼往往需要付出巨大的心力,尤其是在需要適配多種 GPU 架構的情況下。
儘管已有許多庫(如 NVIDIA CUDA-X 和 NVIDIA CUTLASS)旨在幫助開發者挖掘性能,但 CUDA Tile 引入了一種比 SIMT 層級更高的新型 GPU 編程方式。
隨着計算工作負載的演進,特別是在 AI 領域,張量已成為一種基礎數據類型。NVIDIA 開發了專門用於處理張量的硬件,例如 NVIDIA Tensor Core(TC)和 NVIDIA Tensor Memory Accelerator(TMA),它們現已成為每個新 GPU 架構中不可或缺的組成部分。
硬件越複雜,就越需要軟件來幫助駕馭這些能力。CUDA Tile 對 Tensor Core 及其編程模型進行了抽象,使得使用 CUDA Tile 編寫的代碼能夠兼容當前及未來的 Tensor Core 架構。
基於 Tile 的編程方式允許開發者通過指定數據塊(即 Tile),然後定義在這些 Tile 上執行的計算來編寫算法。開發者無需在逐元素的層面上設定算法的執行細節:編譯器和運行時將處理這些工作。
下圖展示了隨 CUDA Tile 推出的 Tile 模型與 CUDA SIMT 模型之間的概念差異。
Tile 模型(左)將數據劃分為多個塊,編譯器將其映射到線程。單指令多線程(SIMT)模型(右)將數據同時映射到塊和線程
這種編程範式在 Python 等語言中很常見,在這些語言中,像 NumPy 這樣的庫可以讓開發者指定矩陣等數據類型,然後用簡單的代碼指定並執行批量操作。
CUDA 軟件更新
以下是本次 CUDA 版本更新中包含的其他重要軟件改進:
運行時對 Green Context(綠色上下文)的支持
CUDA 中的 Green Context 是一種輕量級的上下文形式,可作為傳統 CUDA 上下文的替代方案,為開發者提供更細粒度的 GPU 空間劃分與資源分配能力。
自 CUDA 12.4 起,它們已在驅動 API 中提供;而從本版本開始,Green Context 也正式在運行時 API 中開放使用。
Green Context 使用户能夠定義和管理 GPU 資源的獨立分區,主要是 Streaming Multiprocessors(SM)。你可以將特定數量的 SM 分配給某個特定的 Green Context ,然後在該 context 所擁有的資源範圍內啓動 CUDA kernel 並管理只在此 context 內運行的 stream。
一個典型的應用場景是:你的程序中有部分代碼對延遲極為敏感,並且需要優先於其他所有 GPU 工作執行。通過為這段代碼單獨創建一個 Green Context 並分配 SM 資源,而將剩餘的 SM 分配給另一個 Green Context 處理其他任務,你就能確保始終有可用的 SM 供高優先級計算使用。
CUDA 13.1 還引入了更加可定製的 split () API。開發者可以通過這一接口構建此前需要多次 API 調用才能完成的 SM 分區,並且可以配置工作隊列,從而減少不同 Green Context 之間提交任務時產生的偽依賴(false dependencies)。
有關這些功能及 Green Context 的更多信息,請參見 CUDA Programming Guide。
- CUDA 編程指南地址:https://docs.nvidia.com/cuda/cuda-programming-guide/04-special-topics/green-contexts.html
CUDA 多進程服務(MPS)更新
CUDA 13.1 為多進程服務帶來了多項新特性和功能。有關這些新功能的完整信息,請參閲 MPS 文檔。以下是部分亮點內容:
內存局部性優化分區
內存局部性優化分區(Memory locality optimization partition,MLOPart)是 NVIDIA Blackwell 系列(計算能力 10.0 和 10.3,為架構版本號)及更新 GPU 上提供的一項特性。
該功能允許用户創建專門優化內存局部性的 CUDA 設備。MLOPart 設備基於同一塊物理 GPU 派生而來,但呈現為多個獨立設備,每個設備擁有更少的計算資源和更小的可用內存。
在計算能力 10.0 和 10.3 的 GPU 上,每塊 GPU 都包含兩個分區。
當在 GPU 上啓用 MLOPart 時,每個分區都會作為一個獨立的 CUDA 設備出現,並具有其對應的計算與內存資源。
目前,MLOPart 僅支持 NVIDIA B200 與 NVIDIA B300 系列產品。未來的 CUDA 發佈版本將加入對 NVIDIA GB200 與 NVIDIA GB300 系列的支持。
靜態流式多處理器(SM)分區
作為 MPS 中現有的動態執行資源供給(provisioning)的一種替代方案,靜態流式多處理器(SM)分區是針對 NVIDIA Ampere 架構(計算能力 8.0)及更新 GPU 的一項特性,它為 MPS 客户端提供了一種創建獨佔 SM 分區的方法。
該模式通過使用 -S 或 --static-partitioning 標誌啓動 MPS 控制守護進程來啓用,其主要目的是提供確定性的資源分配,並改善 MPS 客户端之間的隔離性。分區的基本單位是一個「Chunk」(塊),其大小根據 GPU 架構而異 —— 例如,在 Hopper(計算能力 9.0)及更新的獨立 GPU 上,一個 Chunk 包含 8 個 SM。
cuBLAS 中的雙精度和單精度模擬
雖然嚴格來説這不屬於 CUDA 13.1 的更新,但 NVIDIA CUDA Toolkit 13.0 中的 cuBLAS 更新引入了新的 API 和實現,旨在提升雙精度(FP64)矩陣乘法(matmul)的性能。
這是通過在 NVIDIA GB200 NVL72 和 NVIDIA RTX PRO 6000 Blackwell Server Edition 等 GPU 架構的 Tensor Core 上進行浮點(FP)模擬來實現的。
開發者工具
開發者工具是 CUDA 平台的重要組成部分。此次發佈帶來了多項創新和功能增強,包括:
CUDA Tile 核函數性能分析工具
- 在摘要頁新增「Result Type」(結果類型)列,用於區分 Tile 核函數與 SIMT 核函數。
- 詳情頁新增「Tile Statistics」(Tile 統計)部分,總結 Tile 維度和重要管線(pipeline)的利用率。
- 源碼頁支持將指標映射到高層級的 cuTile 核函數源碼。
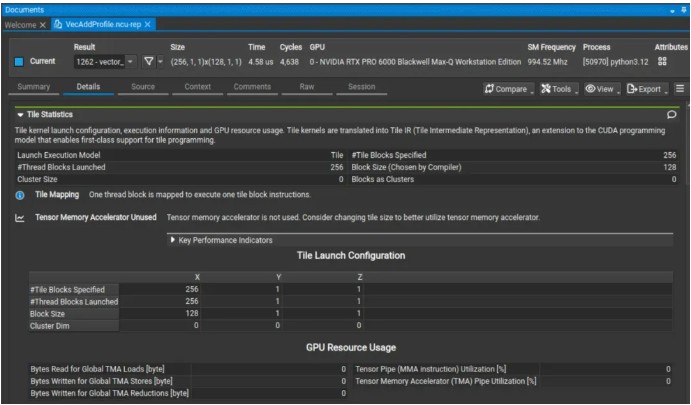
Nsight Compute 分析,重點展示了分析輸出中的 Tile Statistics 部分
此次發佈的 Nsight Compute 還增加了對設備端啓動的圖(device-launched graphs)中 CUDA 圖節點的分析支持,並改進了源碼頁導航,為編譯器生成和用户生成的標籤提供了可點擊的鏈接。
編譯時修補
NVIDIA Compute Sanitizer 2025.4 通過 -fdevice-sanitize=memcheck 編譯器標誌,增加了對 NVIDIA CUDA 編譯器(NVCC)編譯時修補(patching)的支持。這種修補增強了內存錯誤檢測能力,並提升了 Compute Sanitizer 的性能。
編譯時插樁(instrumentation)可將錯誤檢測直接集成到 NVCC 中,從而實現更快的運行速度,並通過高級的基址 - 邊界分析(base-and-bounds analysis)捕捉更隱蔽的內存問題(如相鄰分配間的非法訪問)。這意味着開發者可以在不犧牲速度的情況下調試內存問題,運行更多測試並保持生產力。目前,該功能僅支持 memcheck 工具。
要使用此新功能,請使用如下 NVCC 標誌編譯代碼:
nvcc -fdevice-sanitize=memcheck -o myapp myapp.cu
然後使用 memcheck 工具運行你的應用:
compute-sanitizer --tool memcheck myapp
NVIDIA Nsight Systems
NVIDIA Nsight Systems 2025.6.1 與 CUDA Toolkit 13.1 同步發佈,帶來了多項新的追蹤功能:
- 系統級 CUDA 追蹤:--cuda-trace-scope 可開啓跨進程樹或整個系統的追蹤。
- CUDA 主機函數追蹤:增加了對 CUDA Graph 主機函數節點和 cudaLaunchHostFunc () 的追蹤支持,這些函數在主機上執行並會阻塞流(stream)。
- CUDA 硬件追蹤:在支持的情況下,基於硬件的追蹤現在成為默認模式;使用 --trace=cuda-sw 可恢復為軟件模式。
- Green Context 時間軸行現在會在工具提示中顯示 SM 分配情況,幫助用户理解 GPU 資源利用率。
數學庫
核心 CUDA 工具包數學庫的新功能包括:
- NVIDIA cuBLAS:一項全新的實驗性 API,支持 Blackwell GPU 的分組 GEMM 功能,併兼容 FP8 和 BF16/FP16 數據類型。針對上述數據類型,支持 CUDA 圖的分組 GEMM 提供了一種無需主機同步的實現方式,其設備端形狀可實現最高 4 倍的加速,優於 MoE 用例中的多流 GEMM 實現。
- NVIDIA cuSPARSE:一種新的稀疏矩陣向量乘法 (SpMVOp) API,與 CsrMV API 相比性能有所提升。該 API 支持 CSR 格式、32 位索引、雙精度以及用户自定義的後綴。
- NVIDIA cuFFT:一套名為 cuFFT 設備 API 的全新 API,提供主機函數,用於在 C++ 頭文件中查詢或生成設備功能代碼和數據庫元數據。該 API 專為 cuFFTDx 庫設計,可通過查詢 cuFFT 來生成 cuFFTDx 代碼塊,這些代碼塊可以與 cuFFTDx 應用程序鏈接,從而提升性能。
針對新的 Blackwell 架構,現已推出性能更新。用户可選擇關鍵 API 進行更新,並查看性能更新詳情。
cuBLAS Blackwell 性能
CUDA Toolkit 12.9 在 NVIDIA Blackwell 平台上引入了塊縮放的 FP4 和 FP8 矩陣乘法。CUDA 13.1 增加了對這些數據類型和 BF16 的性能支持。圖 2 顯示了在 NVIDIA Blackwell 和 Hopper 平台上的加速比。

cuSOLVER Blackwell 性能
CUDA 13.1 繼續優化用於特徵分解的批處理 SYEVD 與 GEEV API,並帶來了顯著的性能增強。
其中,批處理 SYEV(cusolverDnXsyevBatched)是 cuSOLVER 中 SYEV 例程的統一批處理版本,用於計算對稱/Hermitian 矩陣的特徵值與特徵向量,非常適合對大量小矩陣進行並行求解的場景。
圖 3 展示了在批大小為 5,000(矩陣行數 24–256)的測試結果。與 NVIDIA L40S 相比,NVIDIA Blackwell RTX Pro 6000 Server Edition 實現了約 2 倍的加速,這與預期的內存帶寬提升相吻合。
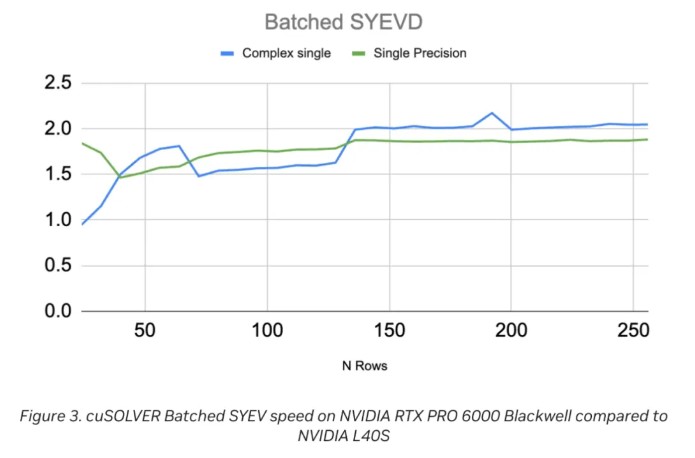
對於複數單精度和實數單精度兩類矩陣,當行數 N = 5 時,加速比約為 1.5×,並隨着行數增大逐漸提升,在 N = 250 時達到 2.0×。
圖 4 顯示了 cusolverDnXgeev (GEEV) 的性能加速比,該函數用於計算一般(非對稱)稠密矩陣的特徵值和特徵向量。GEEV 是一種混合 CPU/GPU 算法。單個 CPU 線程負責在 QR 算法中執行高效的早期降階處理,而 GPU 則處理其餘部分。圖中顯示了矩陣大小從 1,024 到 32,768 的相對性能加速比。
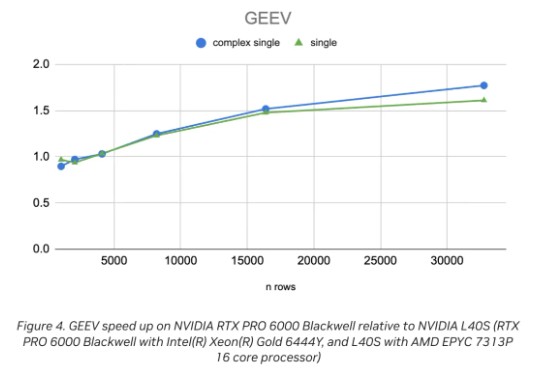
當矩陣行數 n = 5000 時,加速比約為 1.0,並隨着矩陣規模增大逐漸提升,在 n = 30000 時達到約 1.7。
NVIDIA CUDA 核心計算庫
NVIDIA CUDA Core 計算庫 (CCCL) 為 CUB 帶來了多項創新和增強功能。
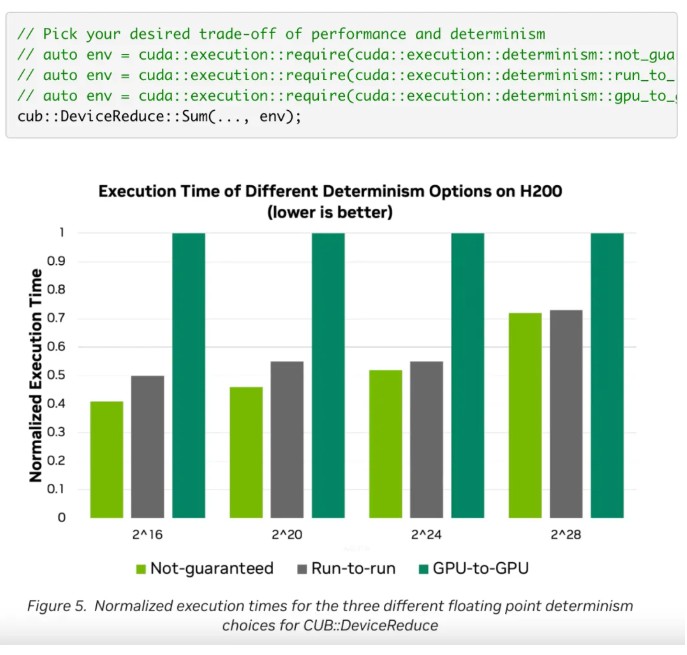
確定性浮點運算簡化
由於浮點加法不具備結合律,cub::DeviceReduce 歷史上只能保證在同一 GPU 上每次運行得到位上完全相同的結果。這被實現為一個兩遍算法。
作為 CUDA 13.1 的一部分, NVIDIA CCCL 3.1 提供了兩個額外的浮點確定性選項,您可以根據這些選項在確定性和性能之間進行權衡。
- 不保證:使用原子操作進行單次歸約。這不能保證提供位上完全相同的結果。
- GPU 間:基於 Kate Clark 在 NVIDIA GTC 2024 大會上演講中可復現的降維結果。結果始終逐位相同。
可以通過標誌位設置確定性選項,如下面的代碼所示。
更便捷的單相 CUB API
幾乎所有 CUB 算法都需要臨時存儲空間作為中間暫存空間。過去,用户必須通過兩階段調用模式來查詢和分配必要的臨時存儲空間,如果兩次調用之間傳遞的參數不一致,這種模式既繁瑣又容易出錯。
CCCL 3.1 為一些接受內存資源的 CUB 算法添加了新的重載,從而用户可以跳過臨時存儲查詢 / 分配 / 釋放模式。

風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
