
Qwen3-TTS family bucket open source launched!

Qwen3-TTS is a series of voice generation tools developed by Qwen, supporting voice cloning, creation, and high-quality human-like voice generation. It utilizes the innovative Qwen3-TTS-Tokenizer-12Hz encoder to achieve efficient compression and strong representational capabilities, supporting 10 languages and various dialects. The model has powerful contextual understanding abilities, capable of adaptively adjusting tone, rhythm, and emotional expression. The 1.7B and 0.6B models of Qwen3-TTS have been open-sourced on GitHub and can be experienced through the Qwen API
Qwen3-TTS is a series of powerful voice generation technologies developed by Qwen, fully supporting voice cloning, voice creation, ultra-high-quality human-like voice generation, and voice control based on natural language descriptions, providing developers and users with the most comprehensive voice generation capabilities.
Relying on the innovative Qwen3-TTS-Tokenizer-12Hz multi-codebook speech encoder, Qwen3-TTS achieves efficient compression and strong representation capabilities of speech signals, not only completely retaining paralinguistic information and acoustic environment features but also enabling high-speed, high-fidelity speech restoration through a lightweight non-DiT architecture. Qwen3-TTS adopts Dual-Track modeling, achieving extreme bidirectional streaming generation speed, with the first audio package requiring only a single character wait.
The entire series of Qwen3-TTS multi-codebook models has been open-sourced, including sizes of 1.7B and 0.6B, where 1.7B can achieve extreme performance with powerful control capabilities, while 0.6B balances performance and efficiency. The models cover 10 mainstream languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian) and various dialect tones, meeting global application needs.
At the same time, the models possess strong contextual understanding capabilities, able to adaptively adjust tone, rhythm, and emotional expression based on instructions and text semantics, with significant improvements in robustness against input text noise. They have been open-sourced on GitHub and can also be experienced through the Qwen API.
Model List
1.7B Model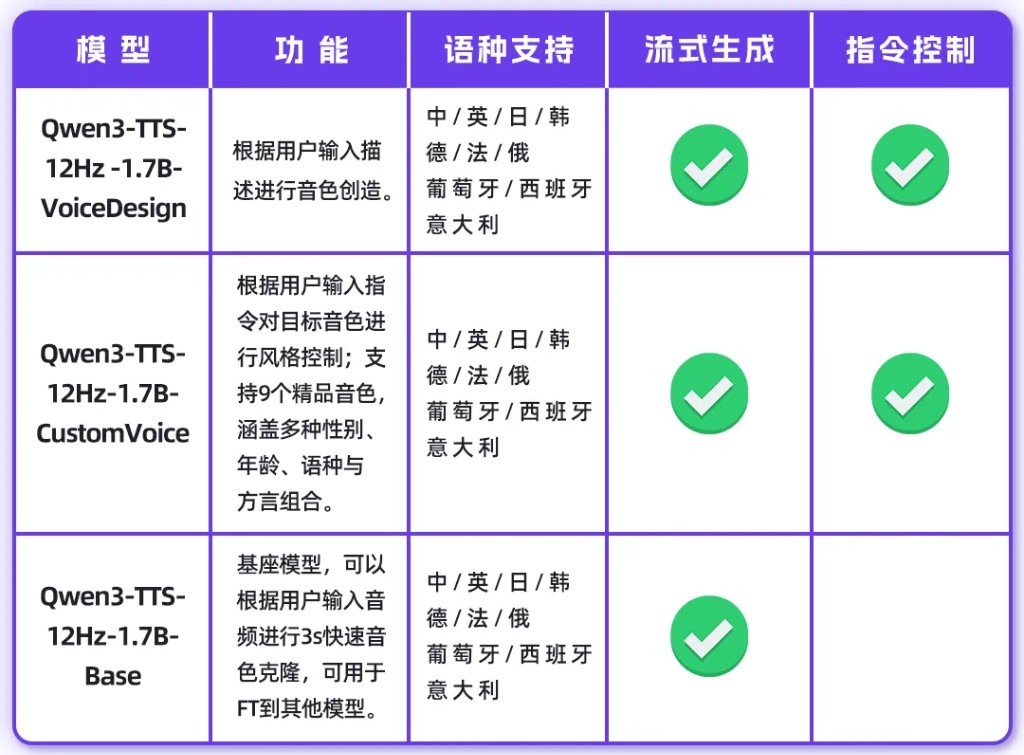
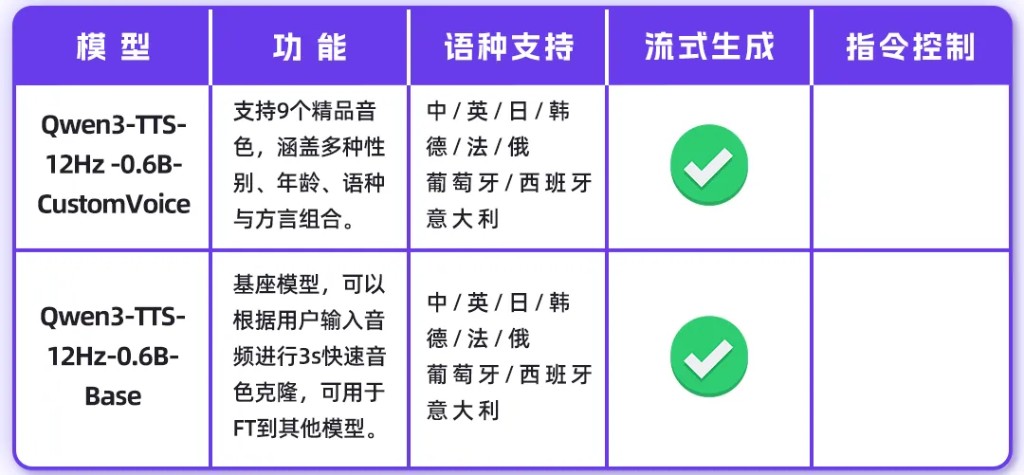
0.6B Model
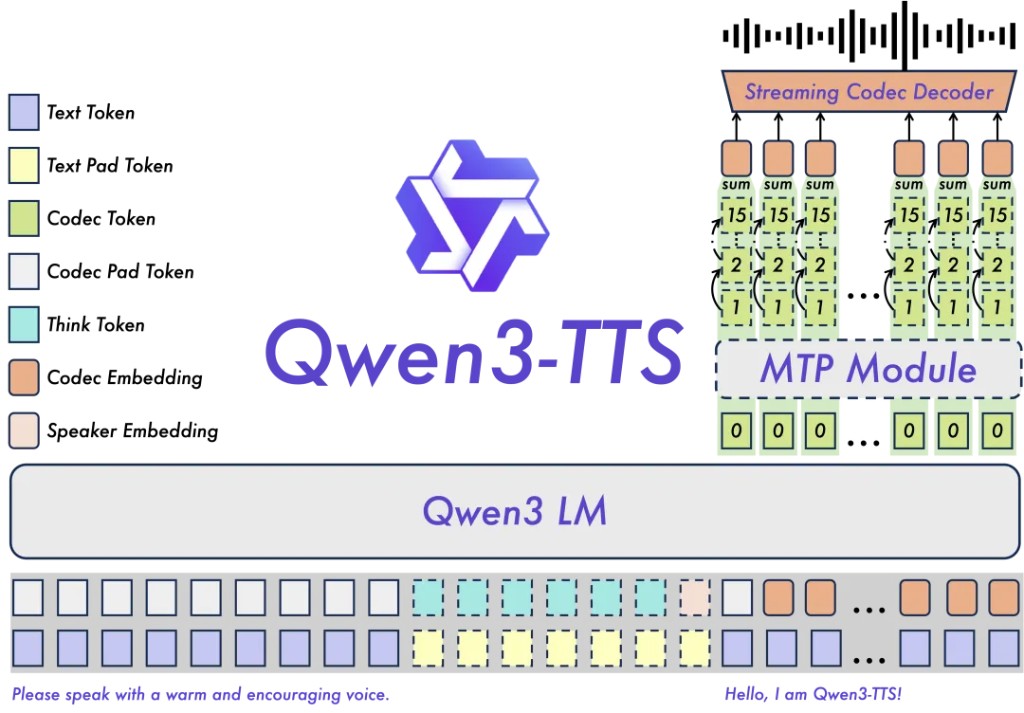
Qwen3-TTS Features
Main features:
- Powerful voice representation: Based on the self-developed Qwen3-TTS-Tokenizer-12Hz, it achieves efficient acoustic compression and high-dimensional semantic modeling of speech signals, completely retaining paralinguistic information and acoustic environment features, and enabling efficient, high-fidelity speech restoration through a lightweight non-DiT architecture.
- Universal end-to-end architecture: Adopting a discrete multi-codebook LM architecture, it achieves end-to-end modeling of all speech information, completely avoiding the information bottleneck and cascading errors of traditional LM+DiT solutions, significantly enhancing the model's universality, generation efficiency, and performance ceiling.
- Extremely low-latency streaming generation: Based on the innovative Dual-Track hybrid streaming generation architecture, a single model is compatible with both streaming and non-streaming generation, with the fastest output of the first audio package immediately after inputting a single character, achieving end-to-end synthesis latency as low as 97ms, meeting the stringent demands of real-time interactive scenarios
Intelligent Text Understanding and Voice Control: Supports voice generation driven by natural language commands, flexibly adjusting multi-dimensional acoustic attributes such as tone, emotion, and rhythm; while deeply integrating text semantic understanding, adaptively adjusting tone, pace, emotion, and rhythm to achieve a humanized expression of "what you think is what you hear."
Model Performance
We conducted a comprehensive evaluation of Qwen3-TTS in terms of tone cloning, creation, and control, with results showing that it achieved SOTA performance across multiple metrics. Specifically:
- In the tone creation task, Qwen3-TTS-VoiceDesign overall surpassed the closed-source model MiniMax-Voice-Design in instruction adherence and generation expressiveness in InstructTTS-Eval, significantly leading other open-source models.
- In the tone control task, Qwen3-TTS-Instruct not only possesses the generalization ability of single-person multilingual capabilities, with an average word error rate of 2.34%; it also maintains style control over tone, achieving a score of 75.4% in InstructTTS-Eval; additionally, it demonstrated excellent long speech generation capability, with a one-time synthesis of 10 minutes of speech having a Chinese and English word error rate of 2.36/2.81%.
- In the tone cloning task, Qwen3-TTS-VoiceClone outperformed MiniMax and SeedTTS in terms of voice stability for Chinese and English cloning on Seed-tts-eval; it achieved an average word error rate of 1.835% and a speaker similarity of 0.789 on the TTS multilingual test set across 10 language items, surpassing MiniMax and ElevenLabs; cross-language tone cloning also exceeded CosyVoice3, ranking SOTA.
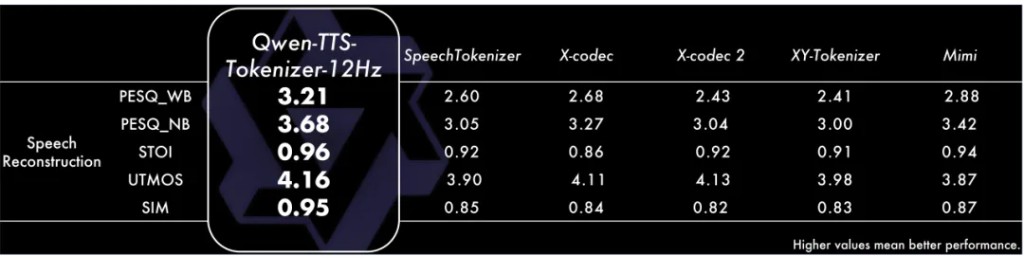
Tokenizer Performance
We evaluated the speech reconstruction performance of Qwen-TTS-Tokenizer, with results from the LibriSpeech test-clean set showing that it achieved SOTA levels on key metrics. Specifically, in the Perceptual Evaluation of Speech Quality (PESQ), Qwen-TTS-Tokenizer scored 3.21 and 3.68 for wideband and narrowband, respectively, significantly leading similar tokenizers.
In Short-Time Objective Intelligibility (STOI) and UTMOS, Qwen-TTS-Tokenizer achieved scores of 0.96 and 4.16, demonstrating excellent restoration quality. In terms of speaker similarity, Qwen-TTS-Tokenizer scored 0.95, significantly surpassing comparison models, indicating its near-lossless speaker information retention capability
Qwen
Risk Warning and Disclaimer
The market has risks, and investment requires caution. This article does not constitute personal investment advice and does not take into account the specific investment goals, financial situation, or needs of individual users. Users should consider whether any opinions, views, or conclusions in this article are suitable for their specific circumstances. Investment based on this is at one's own risk.
