
文心一言如何商业化?百度已有初步落地图谱

对比其他家聚焦协同办公赛道、发布单个独立应用的 “小而美” 路径,百度明显走的是 “大而全” 模式,让智能云大模型平台扮演技术落地 “抓手” 角色,将文心一言能力应用至办公、电商、旅游、金融、政务等场景。
作者 | 张超 编辑 | 罗丽娟
“闭关” 一个多月,百度大语言模型、生成式 AI 产品文心一言公布了首份 “成绩单”:完成 4 次技术版本升级、推理成本降为原来的十分之一、算力利用率提升 1 倍。
虽然这次透露的数据不多,但都是涉及软件技术的关键指标。简言之,文心一言不仅实现了模型性能提升、成本优化,还保持着大约每周升级一次的水平。
从技术研发到场景落地,中间需要一个触达用户的 “抓手”,目前看来,百度智能云大模型平台扮演的就是这个角色。
自 3 月底开始,平台已经向首批企业客户启动内测,目前已经与智能办公、旅行服务、电商直播、政务服务、金融服务等领域客户联合研发,共同打造行业 “样板间”;未来将针对不同客户和开发者的需求,提供多种服务模式。
按照百度的计划,其智能云的六大智能产品系列,都将基于文心一言全面升级,在安全评估完成后上线。
随着 AIGC 浪潮席卷中国,各家互联网大厂掀起了一轮 “大模型混战”,甚至 “默契” 地将协同办公选为了技术落地首站,争抢着发布相关智能化产品。
但百度作为中国第一个发布类 ChatGPT 产品的企业,却是本轮相对较晚公布技术实际应用产品的企业。
不过,对比其他企业聚焦协同办公赛道、发布单个独立应用的 “小而美” 路径,百度明显走的是 “大而全” 模式,直接公布了具备大模型能力的平台,覆盖领域除了办公,还涉及电商、旅游、金融、政务等方面。
需要注意的是,所有这些能力仍处在内测阶段,与全面上线公开使用始终是两回事。
文心一言落地之路,才刚刚开始。
“满月” 成绩首公开
在上海近日举行的一场技术交流会上,百度智能云公布:
自 3 月 16 日公开亮相以来,文心一言推理服务已完成 4 次迭代,目前已升级至 3.5 版本。在业内首创支持动态插入的分布式推理引擎,单机 QPS(每秒查询率)相对线上版本提升 123%。
模型推理效率方面,相对于第一版大模型推理服务,单机 QPS 累计提升近 10 倍。这意味着大模型推理的成本降低为原来十分之一,换句话说,可以并发为原来 10 倍数量的用户提供服务。
模型推理性能方面,已经提升了 50%。性能的提升意味着模型效果提升,即文心一言进化更快了,学习又快又好了。大模型需要在用户反馈中持续不断的学习,推理作为大模型应用的关键,其性能的提升直接影响到产品侧呈现效果。
而在模型算力方面,利用率也提升了 1 倍。据悉,这部分 “降本增效” 贡献的主要来自百度深度学习平台——飞桨。
大模型需要深度学习框架来支撑其高效、稳定的分布式训练。飞桨一方面与大模型的训练和部署进行协同优化,另一方面向下承接芯片,相当于芯片的 “指令集”,适配优化后激发芯片的潜力,从而提升模型算力利用率。
虽然这张 “成绩单” 上的数据不多,但却是关乎模型运行效率、性能、成本等的关键性指标。
随着巨头玩家加入、行业认知加深,越来越多人对大模型研发达成一个共识:这是个 “烧钱” 的行当,没有雄厚资金支持恐怕寸步难行。
研究公司 SemiAnalysis 的首席分析师 Dylan Patel 近期在接受媒体采访时就表示,考虑到 AI 需要昂贵的技术基础设施才能顺畅运行,用户们在 ChatGPT 上撰写求职信、生成课业规划和在约会应用上润色个人简介等操作,每天可能烧掉 OpenAI 多达 70 万美元,每次查询要花掉 36 美分。
这个估算还只是在 ChatGPT-3 模型上,为了根据用户提示快速做出反应,ChatGPT 就需要时刻工作,不断消耗算力。Dylan Patel 判断,ChatGPT-4 的服务开销只会更高。
但任何一次性能升级、算法优化或是算力提升,对大模型研发企业而言,都是一次效率的优化,从另一个角度看也实现了降本,因此没有一家会放弃升级技术。
“我们最近一个月在性能优化上做了非常多的工作,” 百度智能云 AI 与大数据平台总经理忻舟透露,已经通过硬件优化、框架优化让文心一言有了极大提升,但他坦言,从目前可见的技术看,“其实还是有进一步优化空间。”
落地场景和商业化
模型技术的推广,很大程度取决于应用能力和辐射范围。落地,是各科技企业长期要思考解决的议题。
而百度智能云大模型平台,就是文心一言试点落地的 “抓手”。根据百度方面介绍,其智能云大模型平台是 “全球首个一站式企业级大模型平台”,最大特点即 “一站式”,不但提供包括文心一言在内的大模型服务,也支持各类第三方开源大模型,还提供开发 AI 应用的各种工具链及整套环境,旨在打造成大模型生产和分发的集散地。

百度智能云 AI 与大数据平台总经理忻舟
按照服务模式划分,百度智能云大模型平台可根据根据不同企业及开发者需求,提供公有云服务、私有化部署两大服务模式。
其中,在公有云服务方面,百度智能云大模型平台将提供推理、微调和托管三种服务,以降低企业部署大模型的门槛。
从技术层面可以将三大服务能力理解为:推理就是直接调用大模型的推理能力,输出推理结果;微调则是在通用大模型的基础能力上,客户可根据自己的需求,注入少量行业数据,从而用很小成本微调出一个自己专属的大模型;托管指利用通用大模型或者微调出来的行业大模型,直接托管在百度智能云的云端。
在私有化部署方面,百度智能云大模型平台支持软件授权、软硬一体两种方式;前者提供在企业环境中运行的大模型服务,后者则是提供整套大模型服务及对应的硬件基础设施。
实际应用过程中,各种技术能力不可避免会交叉呈现在场景中。百度表示,其是国内唯一将大模型在实际应用中大规模落地的公司,截至目前有 14 万企业申请加入文心一言。
虽然文案创作、智能对话、办公提效、代码生成、数据分析等是目前高频应用场景,但据百度介绍,其正在政务、金融、智能办公、电商、旅游等领域探索测试。
“我们希望能接触更多的场景,给各行各业都做一些样板间。” 忻舟透露,需求量是目前百度考虑将文心一言推广落地的因素之一,会与需求量较高领域的头部企业共同打造标杆、及时地推到市场,同时也想覆盖更多行业、更多场景。
区别于其他家目前集中在协同办公领域的大模型技术展示,百度智能云大模型平台现场不仅呈现了文心一言制作 PPT 的能力,还展示了其在金融、电商等场景下的技术内测情况。
可以看到,在企业办公场景下,用户只要启动 “PPT 生成助手”、文字提出需求 “主题是长安汽车介绍,不超过 10 页”,文心一言即可自动生成内容大纲、设计排版;后续还可以根据用户需求对具体 PPT 进行调整。
百度预计,未来仅需 3 分钟,文心一言就可以做出来一份格式精美、内容丰富的 PPT。
电商场景下,接入文心一言后,用户键入商品基本信息,就可以自动生成不同风格的营销文案,再一键开启数字人直播,便可以帮商家实现 7x24 小时不间断直播带货。
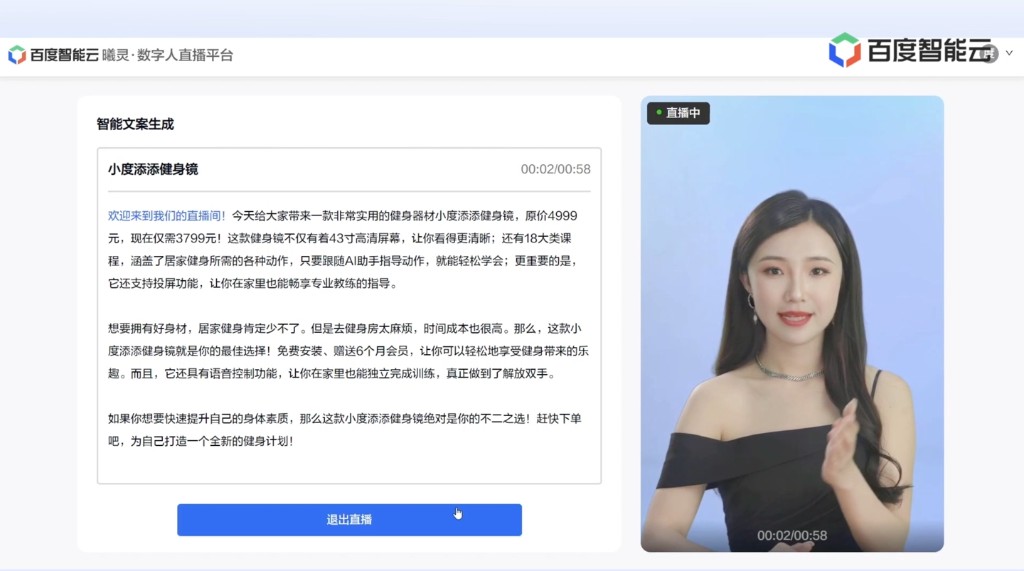
按照忻舟的说法,从技术特点上分析,除了通常看到的微调、指令学习等技术外,百度大模型其实融入了知识图谱和搜索,所以在实时性问题、知识性问题上会做得更好;另外,作为国内最早提出、最早推出 AI 大模型的平台,百度能得到更多、更新的反馈。
所以,即便不少企业都公布了自己的 “AI 助手” 应用,百度仍然认为其在长期竞争中具有优势,但公司并未公布文心一言的调用收费模式。
行业规则正被改写
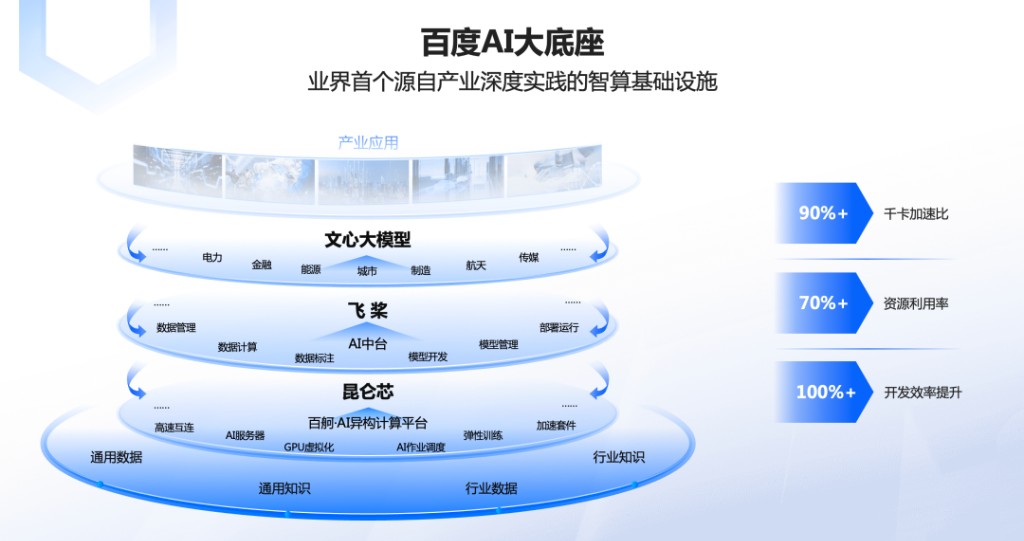
百度文心一言的落地设计,反映出人工智能时代 IT 技术的技术栈一个根本性变化:从过去 “芯片—操作系统—应用” 三层,演化成了 “芯片—框架—模型—应用” 四层。
其中,芯片层,百度有自主研发的 AI 通用处理芯片 “昆仑芯”;接着是飞桨深度学习框架,再到文心预训练大模型和其他业务模型;最上层即搜索、智能云、自动驾驶、小度等应用。
传统机器学习过程,往往是由多个独立模块组成,每个步骤有自己独立的任务,上一步骤模块结果会影响下一步骤模块,从而影响整个训练结果和效率。
对比来看,在端到端深度学习模型下,从输入端到输出端会有一个预测结果,虽然各层在传输过程中会得到一个误差,但模型会进行自我调整,直到得出预期效果结束。
这种端到端的架构,省去了机器学习过程中每个独立模块执行任务时的数据标注成本。
忻舟介绍,就大模型核心技术而言,目前国内外其实是没有代差的,更多差距就体现在工程优化、数据和用户反馈上。
针对数据部分,他进一步解释称,中文语言数据复杂程度远超英文语言,以 “我” 的表达方式为例,英文语境下表达方式就是 “I、me”,而中文里可能有 26 种表达方式,这就增加了数据处理难度。
尤其是在当前百度数据标注工作均由内部工程师和产品经理完成的情况下,一套智能辅助标注系统或者优化算法就显得非常必要。
“谁能够把标数据的成本降低到更低,使得标数据的难度不那么高,这个就是一个核心竞争力。” 忻舟说。
而四层 IT 技术架构的推出,在百度看来,能够实现端到端优化,大幅提升效率;尤其是框架层和模型层之间,有很强的协同作用,可以构建更高效的模型,并显著降低成本。
大模型技术栈的变化,也将彻底改变云计算行业的产业规则,也将为垂类赛道和创新企业带来新的机遇。
一个可见的趋势是,主流商业模式正从 IaaS 变成 MaaS(模型即服务),即按算力、存储等基础设施服务能力收费转向 “模型 + 应用” 收费模式。
百度创始人兼董事长李彦宏就曾预言,未来企业选择云厂商更重要是的看模型好不好,以及芯片、框架、模型、应用这四层之间的协同是否高效。
AI 大模型浪潮开启了一个新时代,当所有产品被重建、规则被重塑,企业面临的除了机遇还有挑战,谁能更快迭代技术、落地产品,谁才能启动增长飞轮。
